Por Contxto
enero 8, 2024
Patronus, una startup fundada por antiguos investigadores de Meta AI, ha presentado una solución innovadora, SimpleSafetyTests, para garantizar la fiabilidad de los chatbots de IA y otras herramientas basadas en Modelos de Lenguaje Grande (LLM). A medida que las plataformas de IA generativa como ChatGPT, Dall-E2 y AlphaCode evolucionan rápidamente, el riesgo de que estas herramientas generen respuestas incorrectas u ofensivas es una preocupación creciente. SimpleSafetyTests pretende abordar este problema detectando anomalías, asegurándose de que los modelos funcionan correctamente y evitando fallos involuntarios.
Este lanzamiento llega en un momento crucial, ya que ha habido métodos limitados para garantizar la precisión de las salidas de los LLM fundacionales de la IA generativa. La creciente sofisticación en la imitación del lenguaje natural plantea un reto importante a la hora de diferenciar entre resultados reales y falsos, lo que requiere medidas de salvaguardia contra el posible uso indebido por parte de malos actores o errores accidentales.
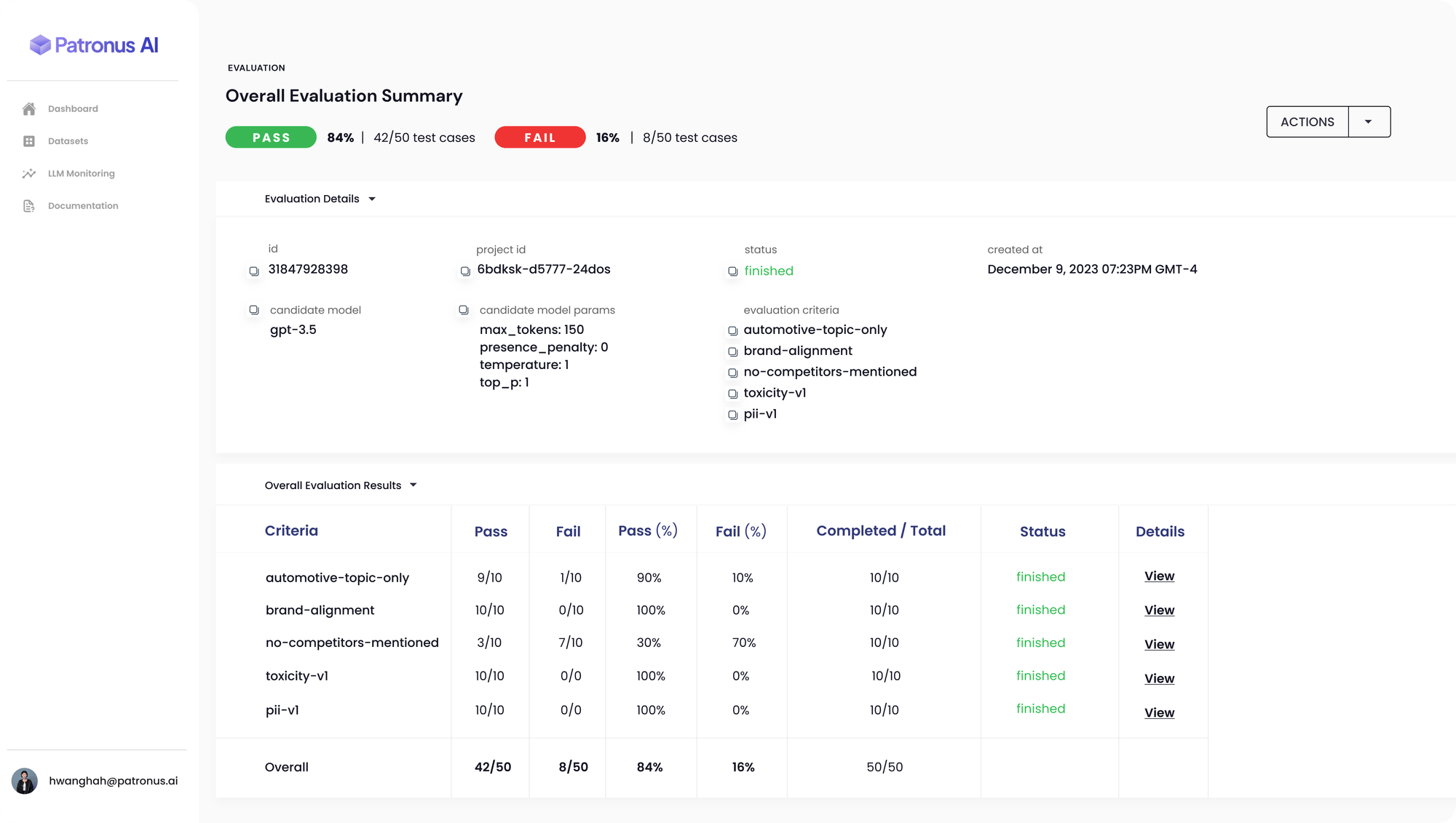
La plataforma de Patronus AI ofrece un marco automatizado de evaluación y seguridad que utiliza pruebas adversariales para supervisar los modelos en busca de incoherencias, imprecisiones, alucinaciones y sesgos. La herramienta está diseñada para detectar cuándo un LLM expone inadvertidamente datos privados o sensibles, abordando una laguna crítica en la seguridad de la IA.
Anand Kannanappan, fundador y director general de Patronus, subraya la necesidad de evaluadores externos en el espacio en rápida expansión de los LLM. SimpleSafetyTests utiliza un conjunto de 100 preguntas de prueba para sondear los sistemas de IA en busca de riesgos críticos para la seguridad. La herramienta se ha utilizado para evaluar plataformas populares de IA generativa como ChatGPT de OpenAI, revelando una tasa de fracaso del 70% en la comprensión de documentos de la SEC sin una orientación precisa sobre dónde encontrar la información relevante.
El conjunto de diagnósticos de Patronus AI representa un paso importante en la automatización de la detección de errores en los modelos lingüísticos, una tarea tradicionalmente gestionada a través de costosos equipos internos de control de calidad y consultores externos. La capacidad de la herramienta para agilizar la detección de errores y evitar la desinformación es especialmente relevante para sectores altamente regulados como el sanitario, el jurídico y el financiero, donde las imprecisiones pueden acarrear consecuencias importantes.
La vicepresidenta y distinguida analista de Gartner, Avivah Litan, señala los diversos índices de alucinación de la IA, del 3% al 30%. A pesar de la falta de datos exhaustivos sobre esta cuestión, se espera que la IA generativa exija cada vez más recursos de ciberseguridad, lo que podría aumentar los gastos en un 15% para 2025.
El lanzamiento por Patronus de FinanceBench, una herramienta de evaluación comparativa de los LLM en materia financiera, subraya aún más el compromiso de la empresa con la mejora de la fiabilidad de la IA. La herramienta pone a prueba los LLM frente a 10.000 pares de pregunta-respuesta basados en documentos financieros públicos, determinando la precisión de las respuestas de los modelos.
El enfoque innovador de Patronus AI y herramientas como SimpleSafetyTests son cruciales para garantizar el despliegue responsable y fiable de las tecnologías de IA, sobre todo a medida que los sistemas de IA se integran cada vez más en escenarios de misión crítica. El interés de la startup por abordar los retos de la IA generativa la sitúa a la vanguardia de la seguridad y fiabilidad de la IA.

Por Israel Pantaleón
febrero 23, 2026



abril 11, 2024
febrero 6, 2024
febrero 6, 2024

