Por Contxto
January 8, 2024
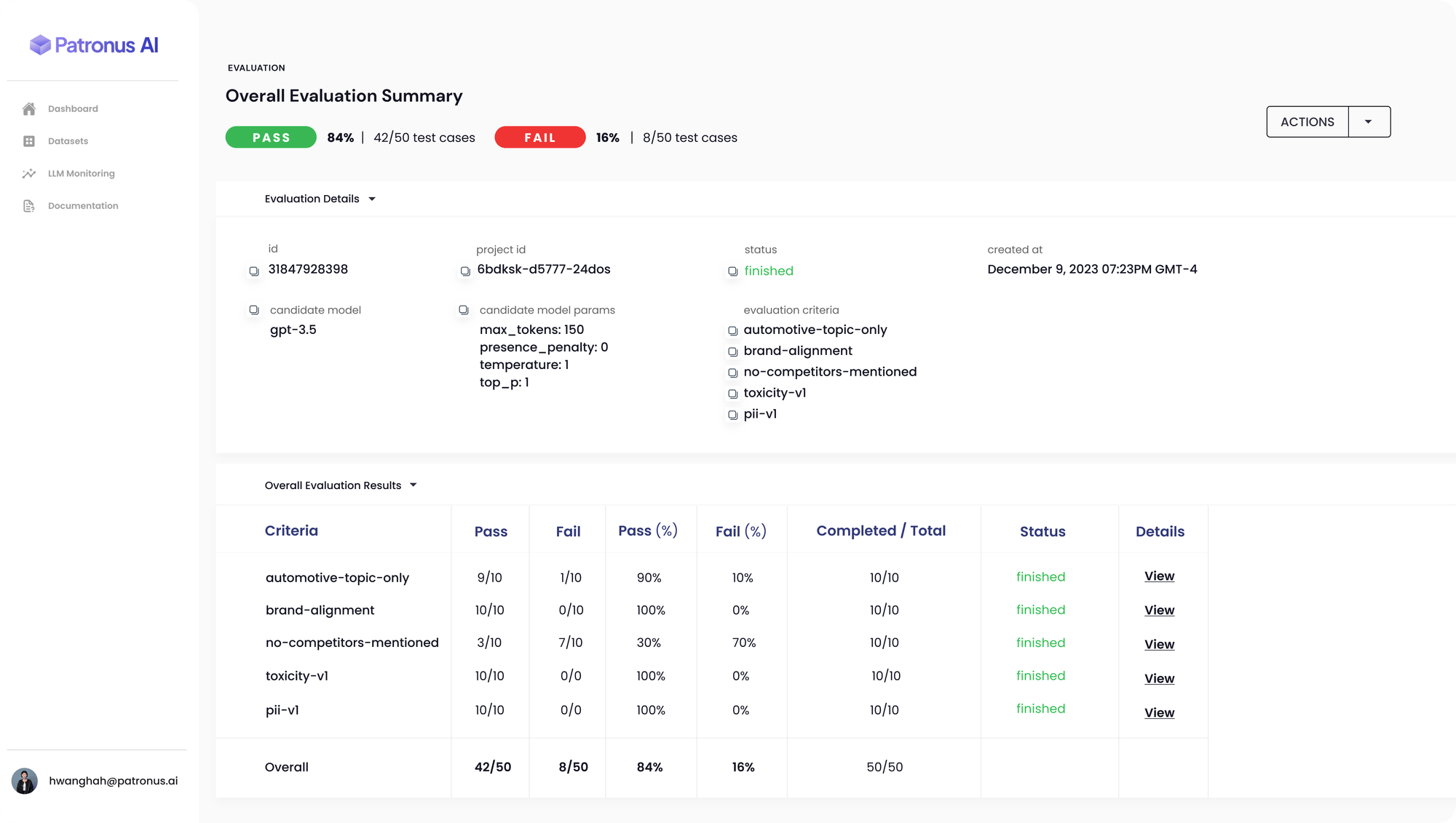
Patronus, a startup founded by former Meta AI researchers, has unveiled a groundbreaking solution, SimpleSafetyTests, to ensure the reliability of AI chatbots and other Large Language Models (LLM) based tools. As generative AI platforms like ChatGPT, Dall-E2, and AlphaCode rapidly evolve, the risk of these tools generating incorrect or offensive responses is a growing concern. SimpleSafetyTests aims to address this by detecting anomalies, ensuring models function correctly, and preventing unintentional failures.
This launch comes at a crucial time, as there have been limited methods to guarantee the accuracy of outputs from generative AI’s foundational LLMs. The increasing sophistication in mimicking natural language poses a significant challenge in differentiating between real and false results, necessitating safeguarding measures against potential misuse by bad actors or accidental errors.
Patronus AI’s platform offers an automated evaluation and safety framework that uses adversarial testing to monitor models for inconsistencies, inaccuracies, hallucinations, and biases. The tool is designed to detect when a LLM inadvertently exposes private or sensitive data, addressing a critical gap in AI safety.
Anand Kannanappan, founder and CEO of Patronus, emphasizes the need for third-party evaluators in the rapidly expanding LLM space. SimpleSafetyTests utilizes a set of 100 test prompts to probe AI systems for critical safety risks. The tool has been used to assess popular generative AI platforms like OpenAI’s ChatGPT, revealing a 70% failure rate in understanding SEC documents without precise guidance on where to find relevant information.
Patronus AI’s diagnostics suite represents a significant step in automating error detection in linguistic models, a task traditionally managed through costly internal quality control teams and external consultants. The tool’s ability to streamline error detection and prevent misinformation is particularly relevant for highly regulated sectors like healthcare, legal, and finance, where inaccuracies can lead to significant consequences.
Gartner’s vice president and distinguished analyst, Avivah Litan, notes the varying hallucination rates of AI, from 3% to 30%. Despite the lack of comprehensive data on this issue, the expectation is that generative AI will increasingly demand more cybersecurity resources, potentially raising expenses by 15% by 2025.
Patronus’s launch of FinanceBench, a benchmarking tool to evaluate LLMs in financial matters, further underscores the company’s commitment to enhancing AI reliability. The tool tests LLMs against 10,000 question-answer pairs based on public financial documents, determining the accuracy of the models’ responses.
Patronus AI’s innovative approach and tools like SimpleSafetyTests are crucial in ensuring the responsible and reliable deployment of AI technologies, particularly as AI systems become increasingly integrated into mission-critical scenarios. The startup’s focus on addressing the challenges of generative AI positions it at the forefront of AI safety and reliability.




